Appropriate age rating by the US-based rating agency
genre
Film category
let’s do some touches on the dataset
Get rid of the blank X1 Variable.
Change release date into an actual date.
change character variables to factors
Calculate the return on investment as the worldwide_gross/production_budget.
Calculate the percentage of total gross as domestic revenue.
Get the year, month, and day out of the release date.
Remove rows where the revenue is $0 (unreleased movies, or data integrity problems), and remove rows missing information about the distributor. Go ahead and remove any data where the rating is unavailable also.
…. but before that lets skim a bit!
out_new |> skimr::skim()
Data summary
Name
out_new
Number of rows
3401
Number of columns
9
_______________________
Column type frequency:
character
5
numeric
4
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
release_date
0
1.00
8
10
0
1768
0
movie
0
1.00
1
35
0
3400
0
distributor
48
0.99
3
22
0
201
0
mpaa_rating
137
0.96
1
5
0
4
0
genre
0
1.00
5
9
0
5
0
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
…1
0
1
1701
981.93
1
851
1701
2551
3401
▇▇▇▇▇
production_budget
0
1
33284743
34892390.59
250000
9000000
20000000
45000000
175000000
▇▂▁▁▁
domestic_gross
0
1
45421793
58825660.56
0
6118683
25533818
60323786
474544677
▇▁▁▁▁
worldwide_gross
0
1
94115117
140918241.82
0
10618813
40159017
117615211
1304866322
▇▁▁▁▁
mov <- out_new |>select(-1) |>mutate(release_date =mdy(release_date)) |>#mdy is the setup of the date variablemutate_if(is.character,as.factor) |>mutate(roi = worldwide_gross / production_budget) |>mutate(pct_domestic = domestic_gross / worldwide_gross) |>mutate(year =year(release_date)) |>mutate(month =month(release_date)) |>mutate(day =as.factor(wday(release_date))) |>arrange(desc(release_date)) |>filter(worldwide_gross >0) |>filter(!is.na(distributor)) |>filter(!is.na(mpaa_rating))mov#> # A tibble: 3,202 × 13#> release_date movie production_budget domestic_gross worldwide_gross#> <date> <fct> <dbl> <dbl> <dbl>#> 1 2018-10-12 First Man 60000000 30000050 55500050#> 2 2018-10-12 Goosebumps 2: … 35000000 28804812 39904812#> 3 2018-10-05 Venom 100000000 171125095 461825095#> 4 2018-10-05 A Star is Born 36000000 126181246 200881246#> 5 2018-09-28 Smallfoot 80000000 66361035 137161035#> 6 2018-09-28 Night School 29000000 66906825 84406825#> 7 2018-09-28 Hell Fest 5500000 10751601 12527795#> 8 2018-09-14 The Predator 88000000 50787159 127987159#> 9 2018-09-14 White Boy Rick 30000000 23851700 23851700#> 10 2018-08-17 Mile 22 35000000 36108758 64708758#> # ℹ 3,192 more rows#> # ℹ 8 more variables: distributor <fct>, mpaa_rating <fct>, genre <fct>,#> # roi <dbl>, pct_domestic <dbl>, year <dbl>, month <dbl>, day <fct>
fair enough , the date variable looks pretty good now !
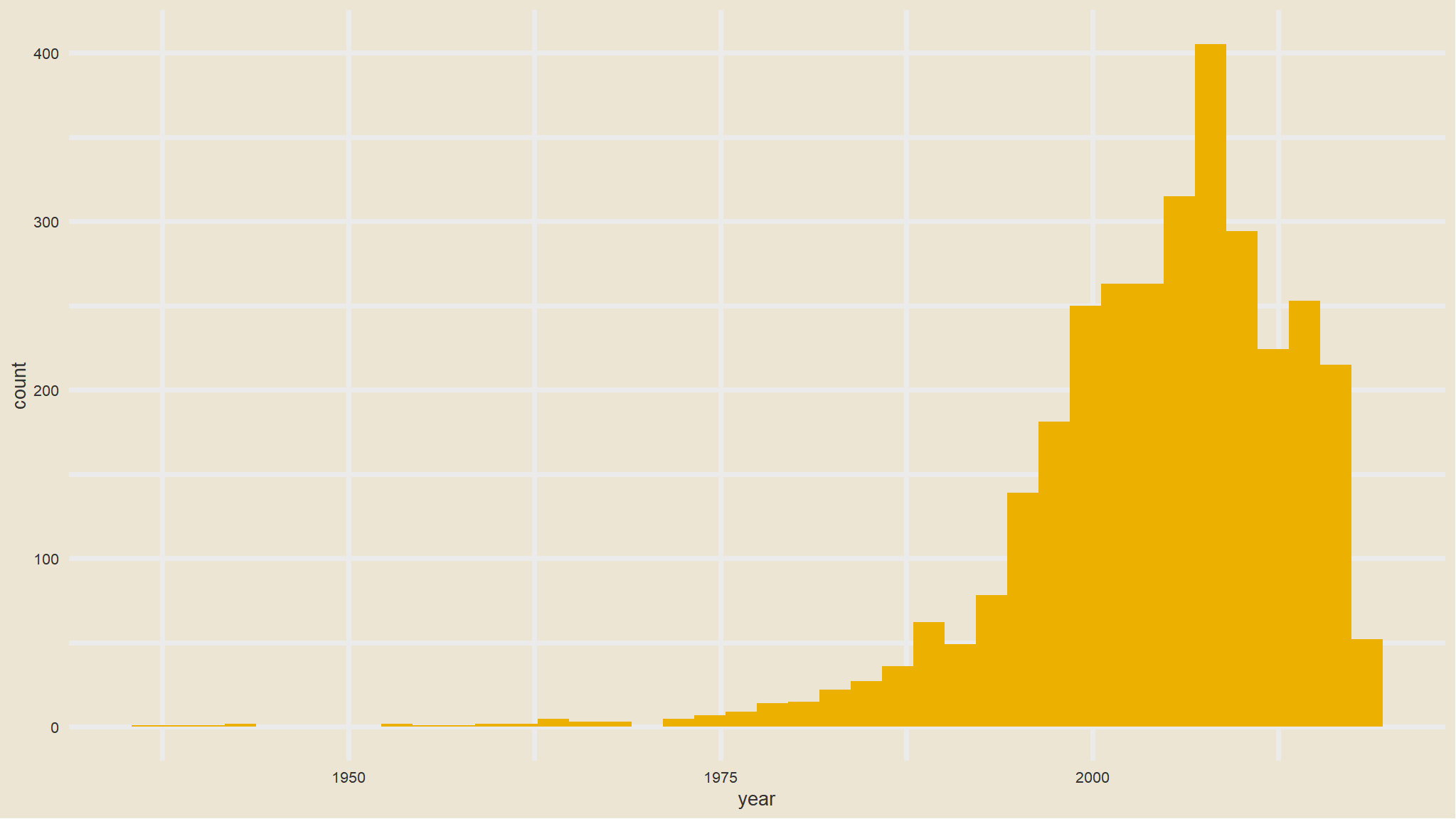
let us look at the distribution of the year variable
There doesn’t appear to be much documented before 1975, so let’s restrict (read: filter) the dataset to movies made since 1975. Also, we’re going to be doing some analyses by year, and the data for 2018 is still incomplete, let’s remove all of 2018. Let’s get anything produced in 1975 and after (>=1975) but before 2018.
filter and remove the years described above
mov<-mov |>filter(year>=1975& year <2018)ggplot(mov, aes(year)) +geom_histogram(bins=40, fill=avatar_pal()(1))+theme_avatar()+labs(title="distribution of year")
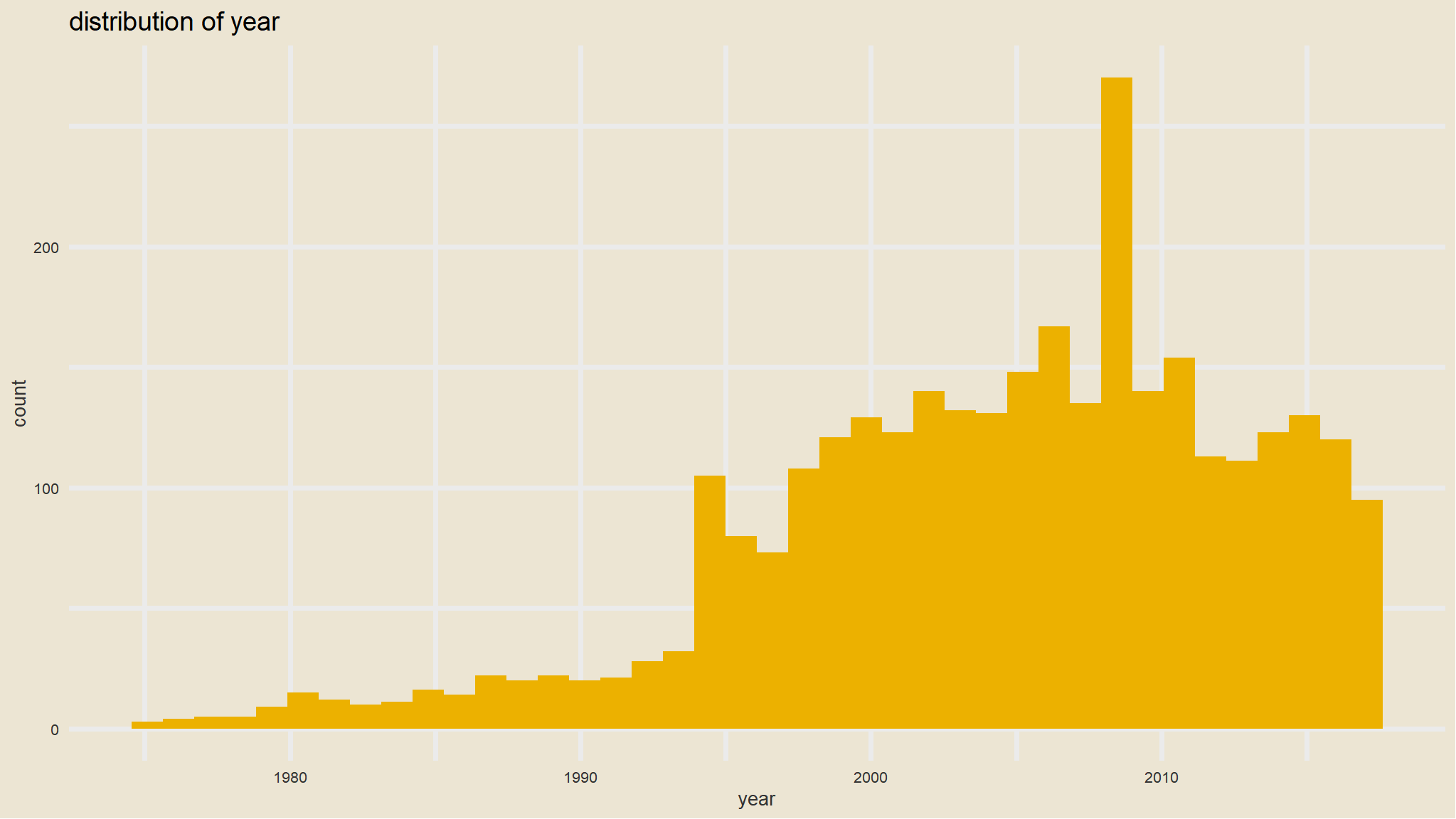
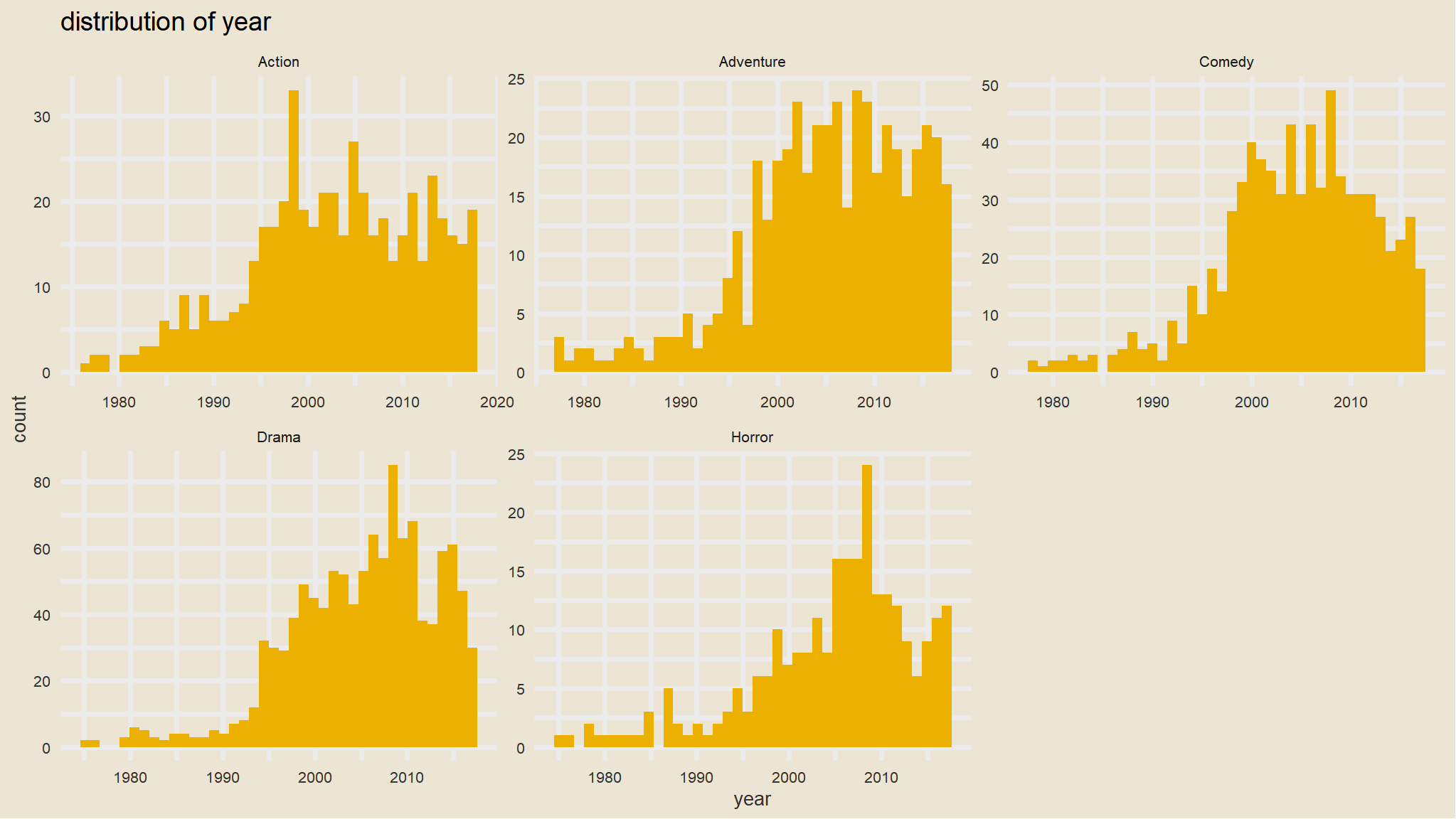
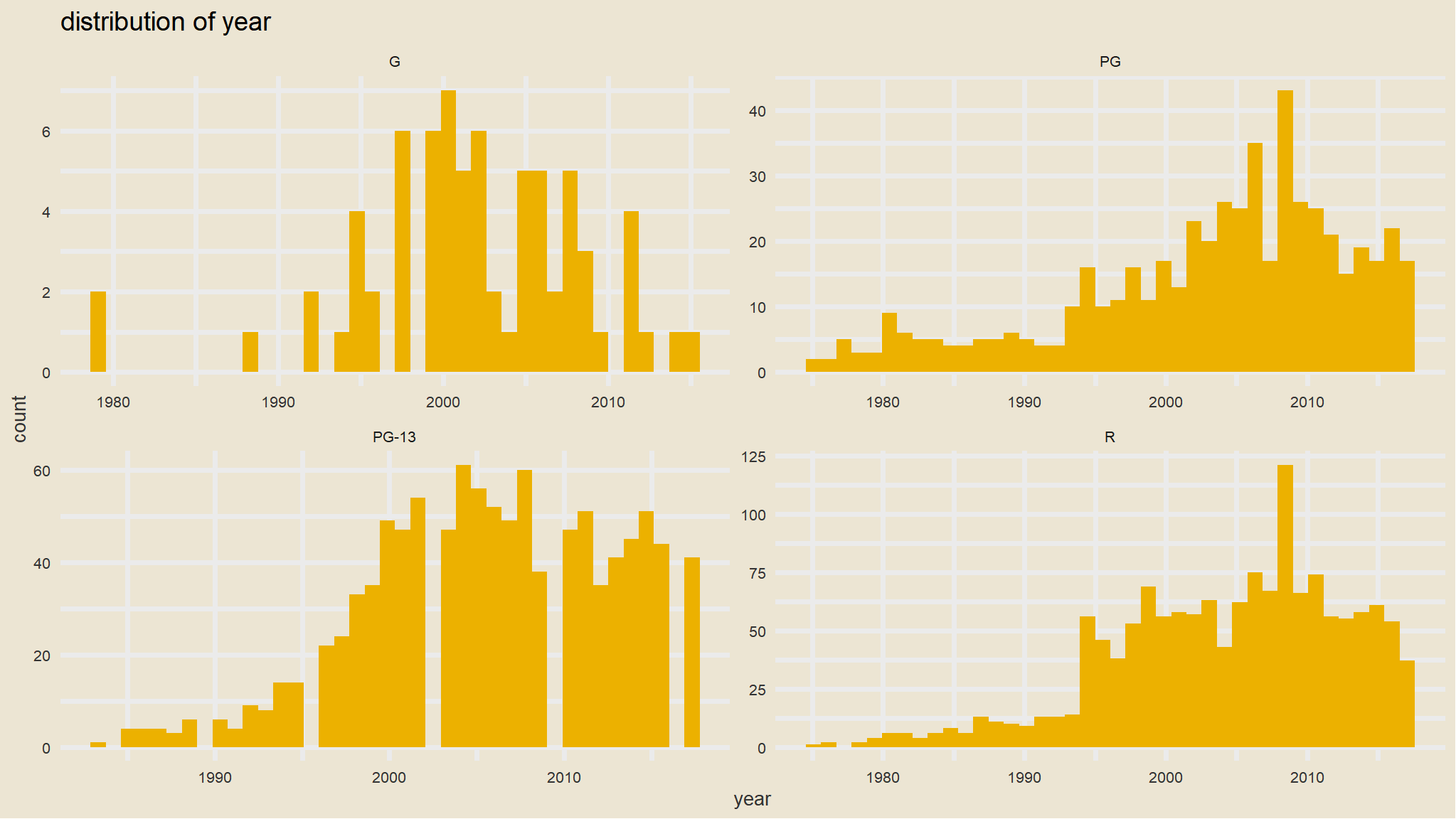
that looks awesome ,we can picture that by genre or rating as well
ggplot(mov, aes(year)) +geom_histogram(bins=40, fill=avatar_pal()(1))+theme_avatar()+facet_wrap(~genre,scales="free")+labs(title="distribution of year")
ggplot(mov, aes(year)) +geom_histogram(bins=40, fill=avatar_pal()(1))+theme_avatar()+facet_wrap(~mpaa_rating,scales="free")+labs(title="distribution of year")
Days the movies were released
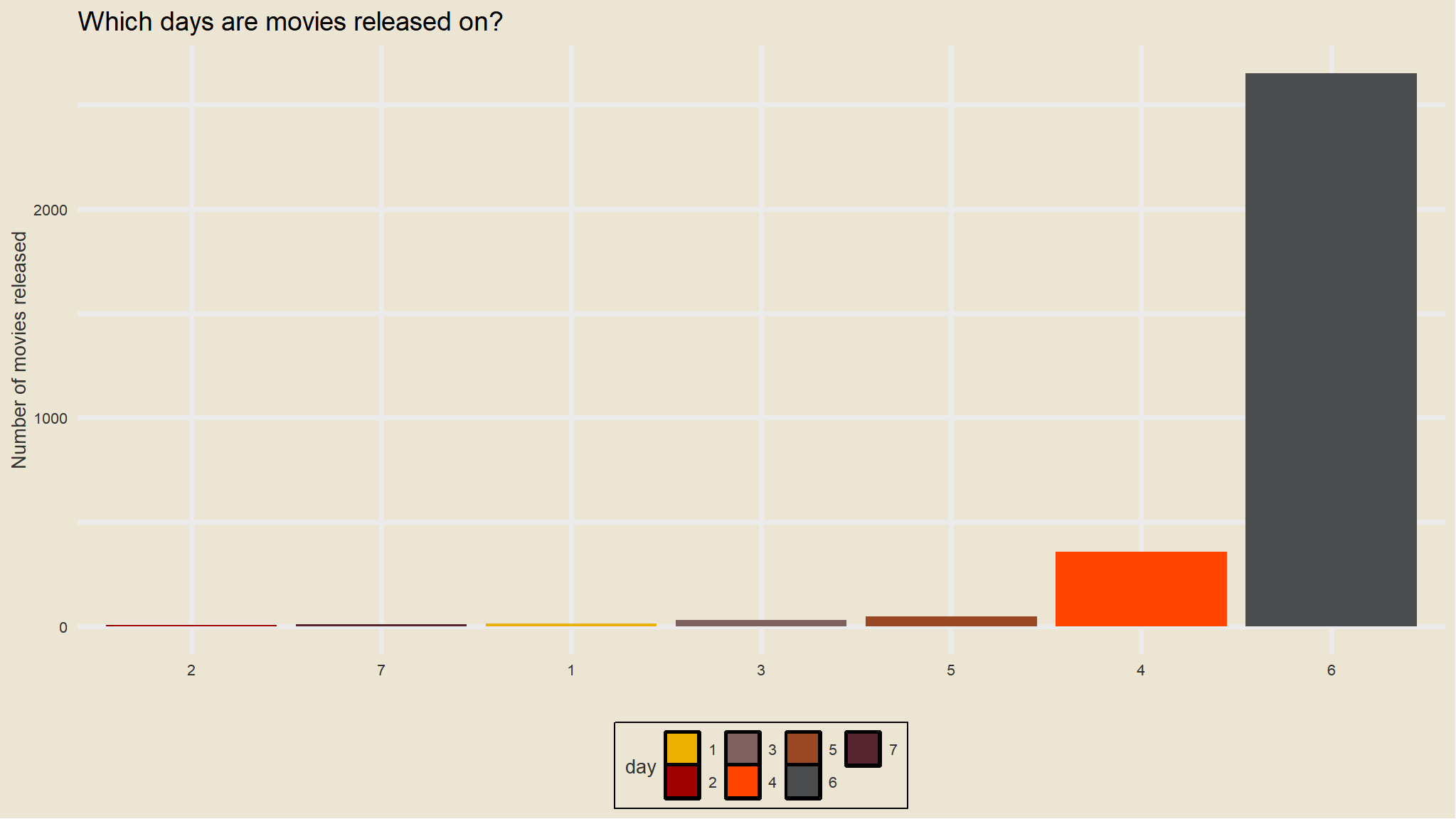
library(ggthemes)mov |>count(day, sort=TRUE) |>ggplot(aes(y=n,x=fct_reorder(day,n),fill=day)) +geom_col() +labs(x="", y="Number of movies released", title="Which days are movies released on?") +theme_avatar() +scale_fill_avatar()
most movies were watched on a Friday (Friday night maybe)
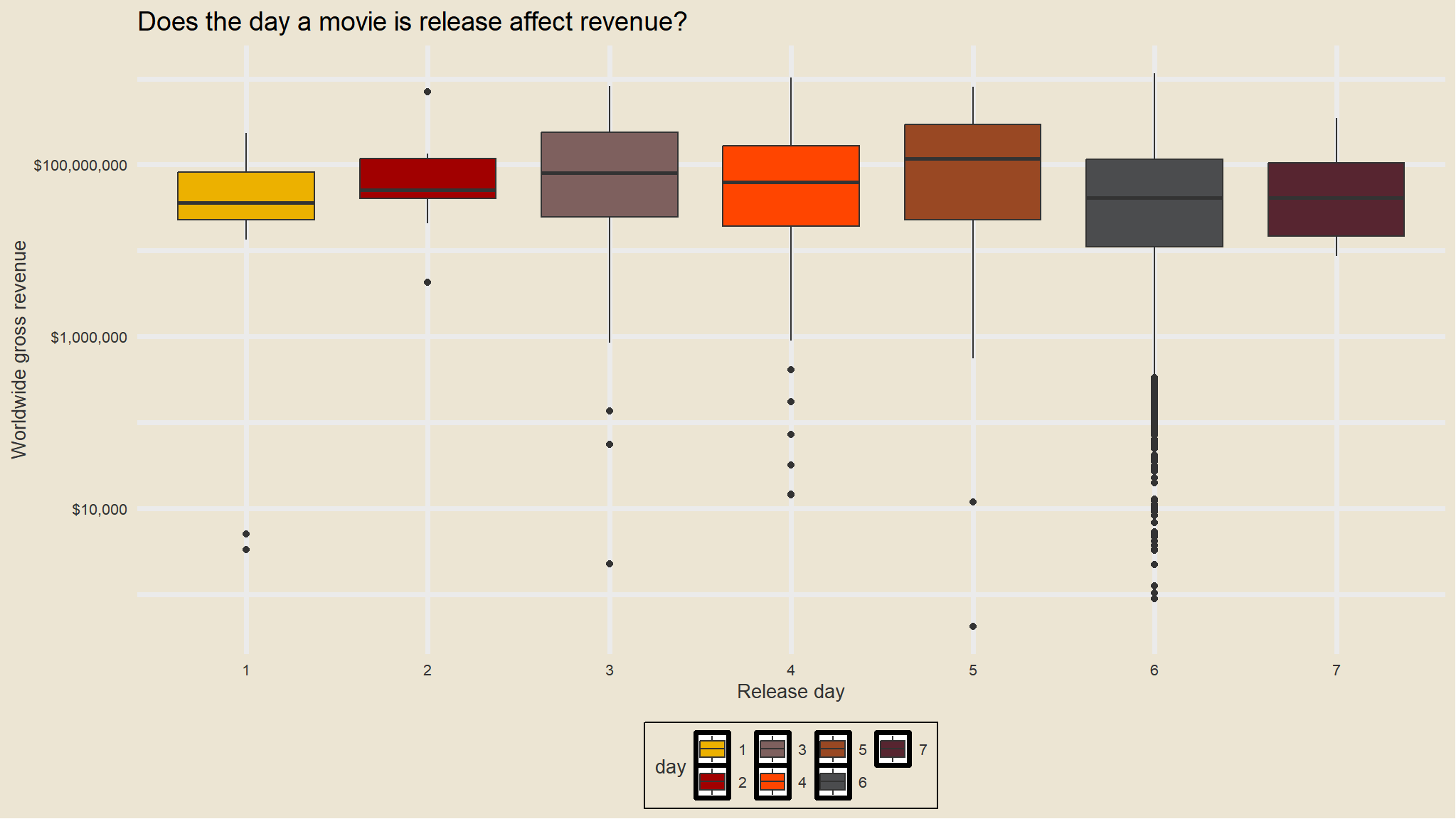
library(scales)mov |>ggplot(aes(day, worldwide_gross,fill=day)) +geom_boxplot() +scale_y_log10(labels=dollar_format()) +labs(x="Release day",y="Worldwide gross revenue", title="Does the day a movie is release affect revenue?") +scale_fill_avatar()+theme_avatar()
model<-aov(worldwide_gross~day,data=mov)summary(model)#> Df Sum Sq Mean Sq F value Pr(>F) #> day 6 1.178e+18 1.963e+17 9.961 6.44e-11 ***#> Residuals 3110 6.129e+19 1.971e+16 #> ---#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
\(H_0\) : there is no difference in means
\(H_1\) : means are different
since p-value is less than 0.05 we reject null hypothesis and conclude that the difference in mean gross is statistically significant
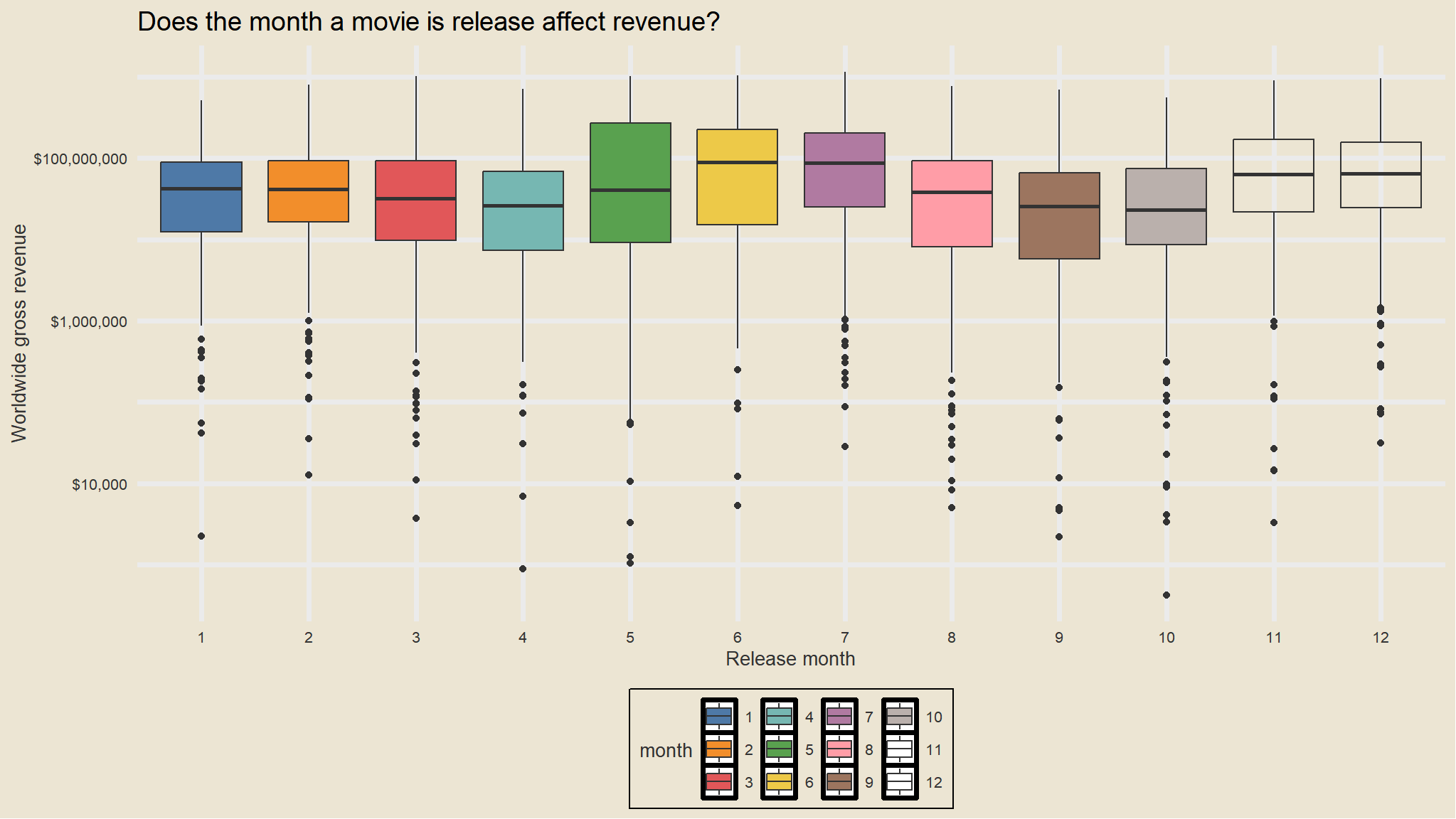
what about month?
library(scales)mov |>ggplot(aes(factor(month), worldwide_gross,fill=factor(month))) +geom_boxplot() +scale_y_log10(labels=dollar_format()) +labs(x="Release month",y="Worldwide gross revenue", title="Does the month a movie is release affect revenue?",fill="month") +scale_fill_tableau()+theme_avatar()
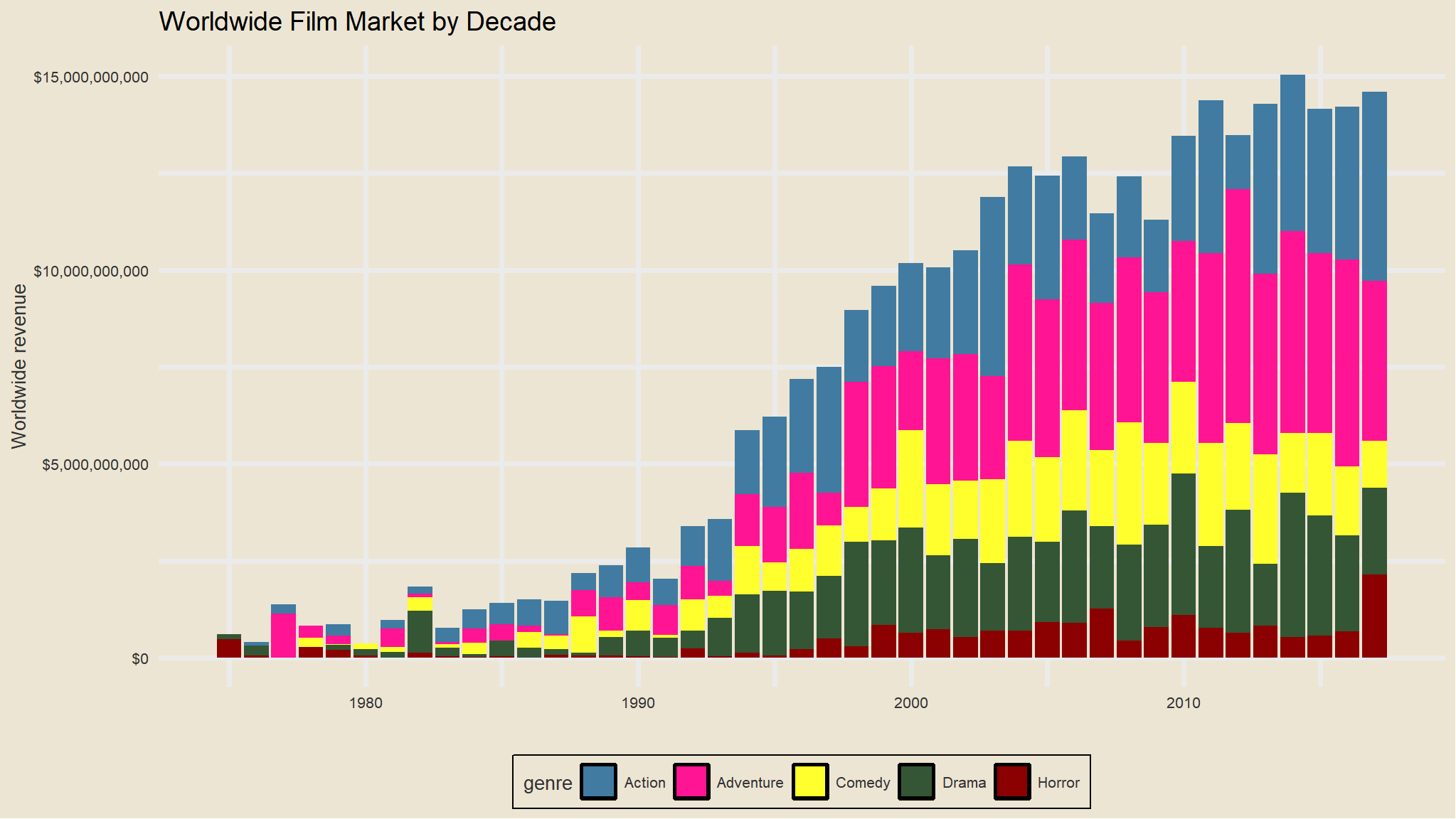
What does the worldwide movie market look like by decade? Let’s first group by year and genre and compute the sum of the worldwide gross revenue. After we do that, let’s plot a barplot showing year on the x-axis and the sum of the revenue on the y-axis, where we’re passing the genre variable to the fill aesthetic of the bar.
mov |>group_by(year, genre) |>summarise(revenue=sum(worldwide_gross)) |>ggplot(aes(year, revenue)) +geom_col(aes(fill=genre)) +scale_y_continuous(labels=dollar_format()) +labs(x="", y="Worldwide revenue", title="Worldwide Film Market by Decade")+theme_avatar()+scale_fill_gravityFalls()
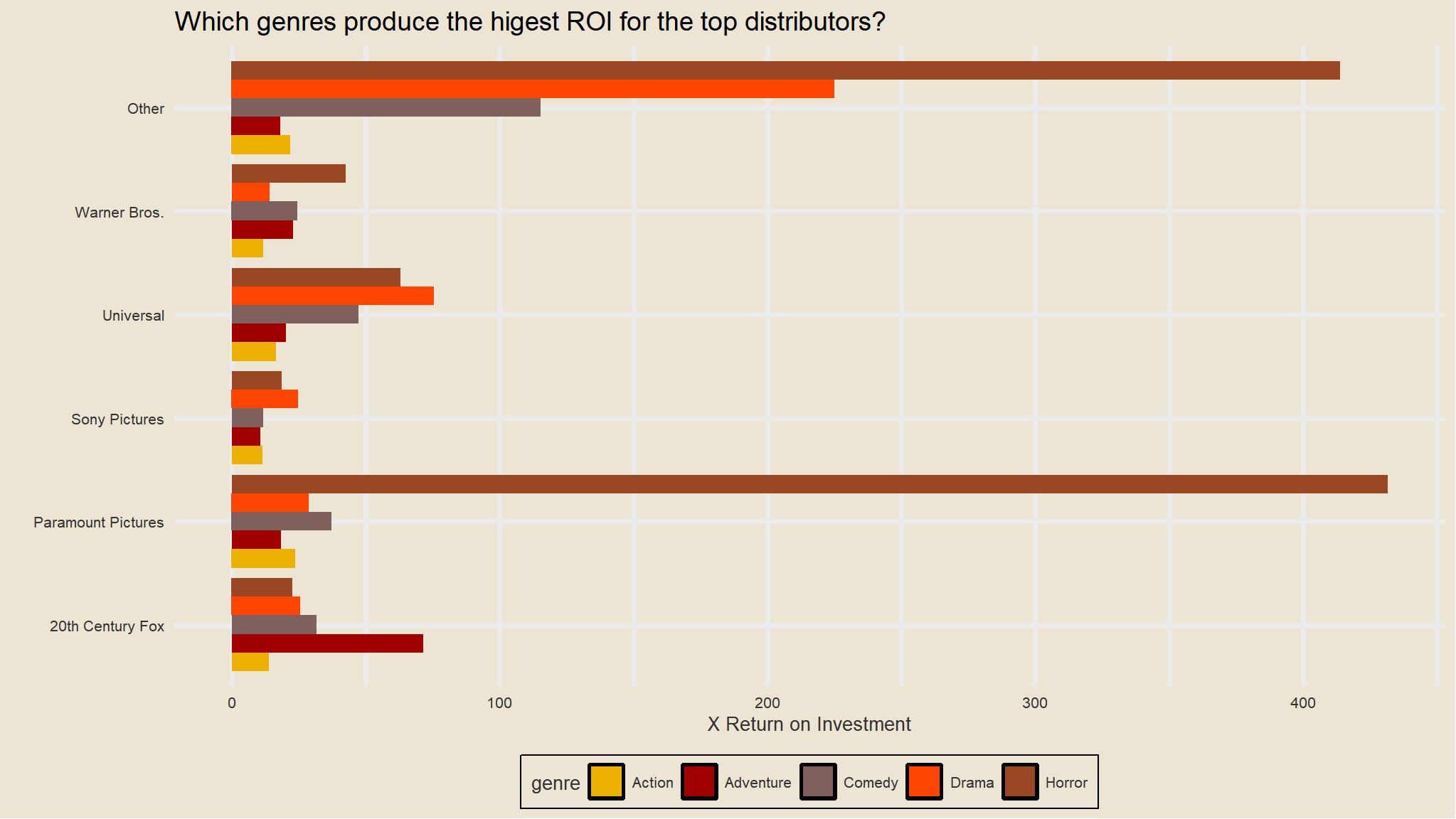
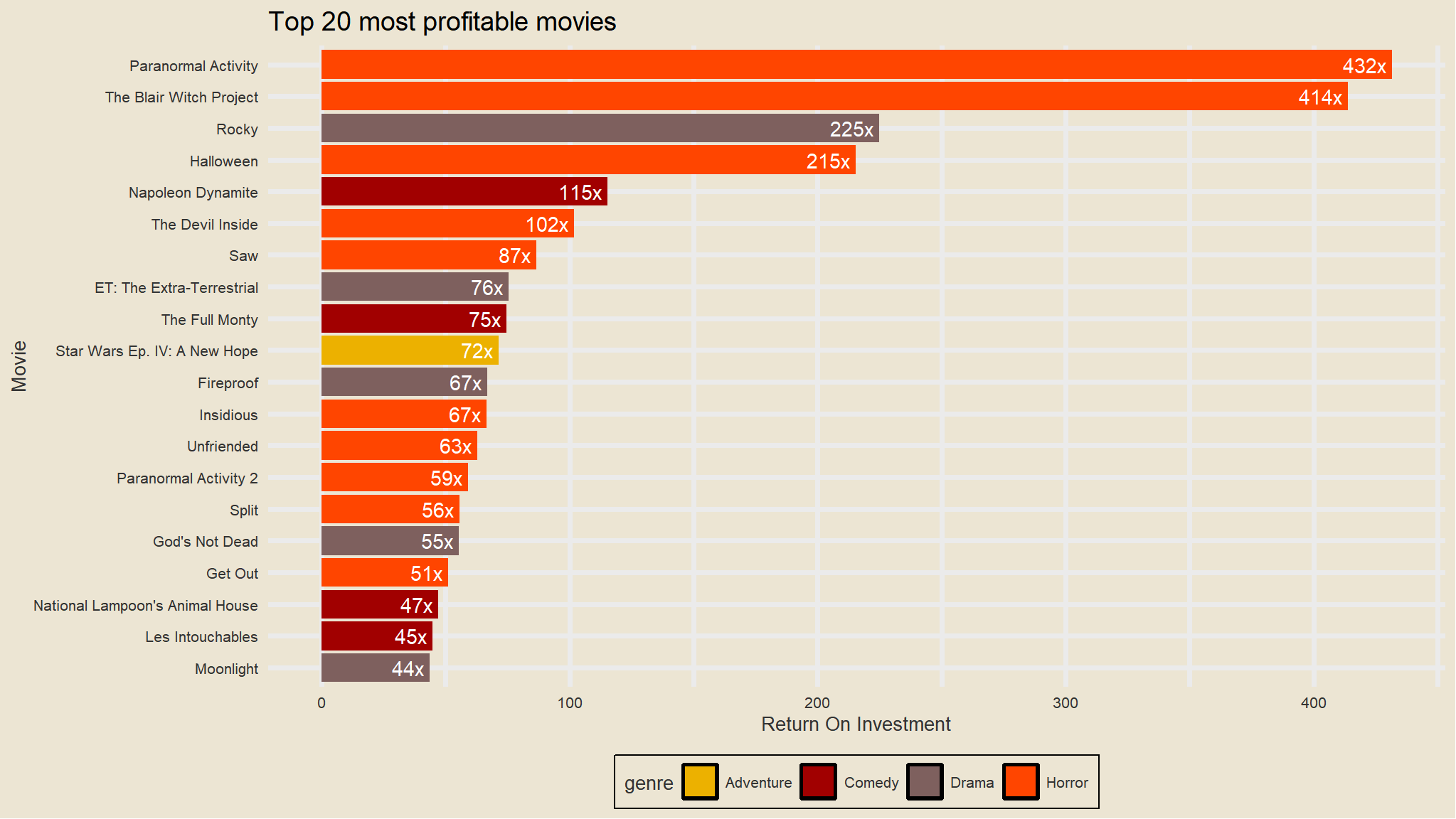
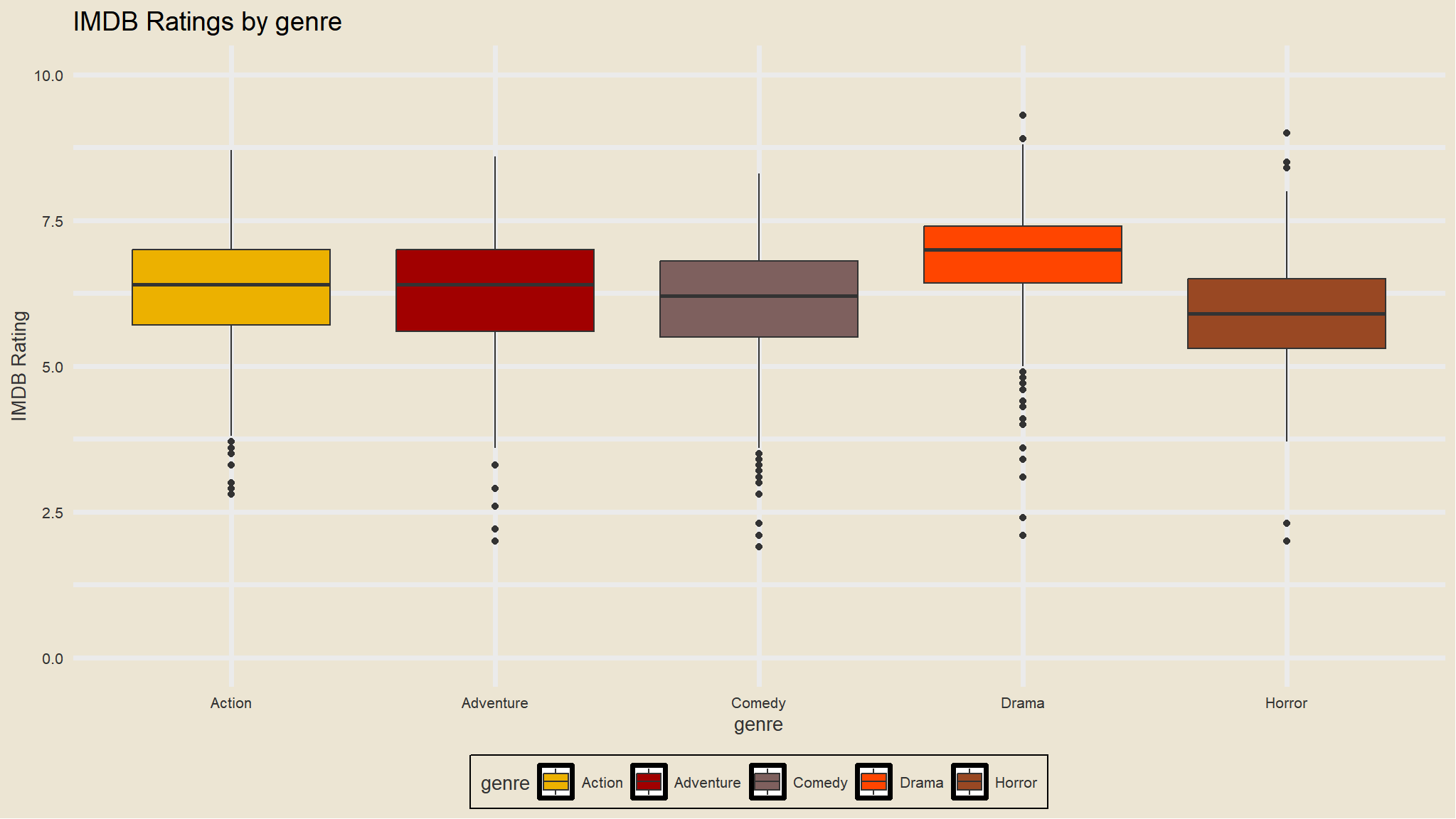
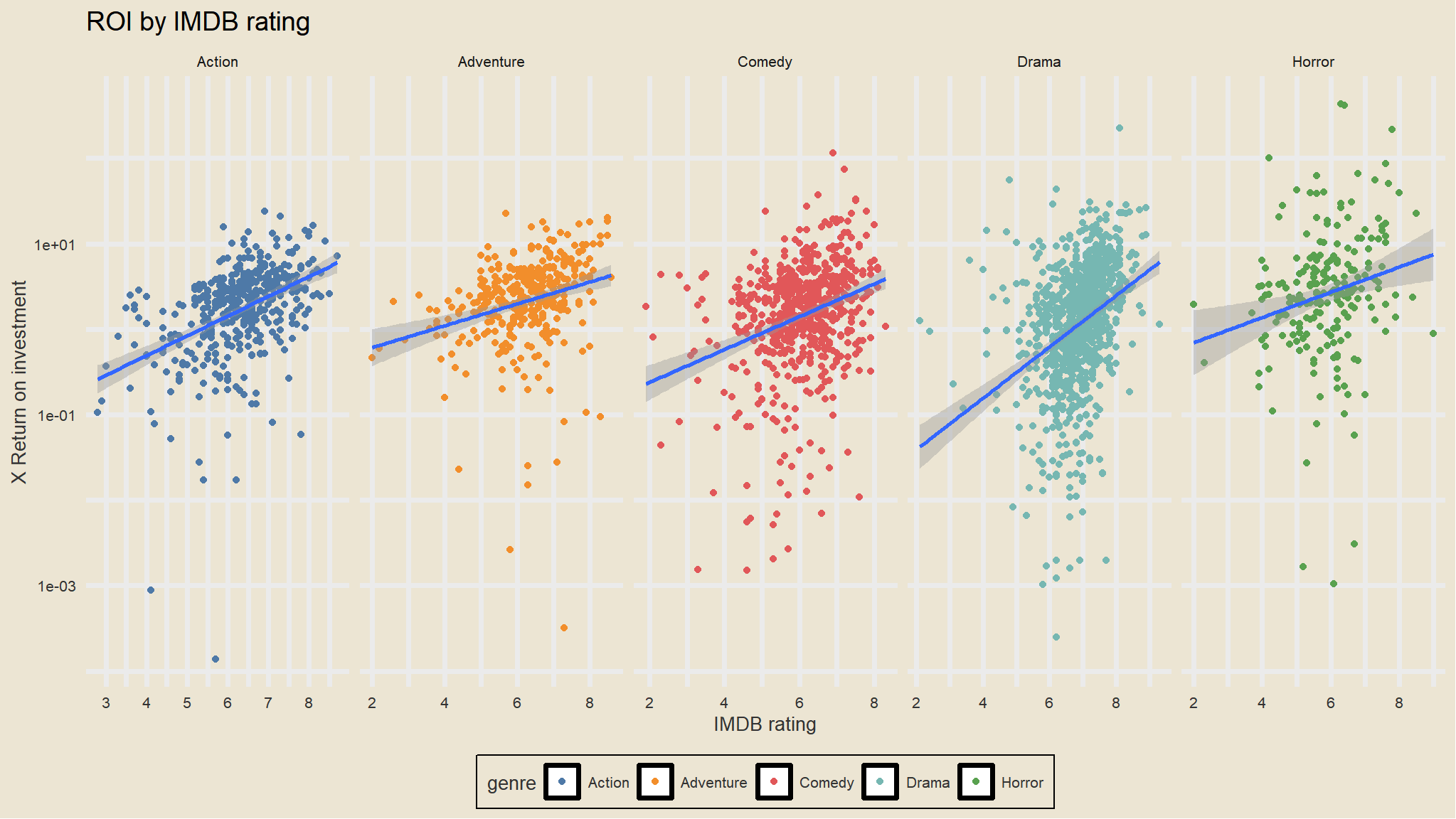
Which genres produce the highest Return on investment?
looks like horror movies and drama take the lead .
next up
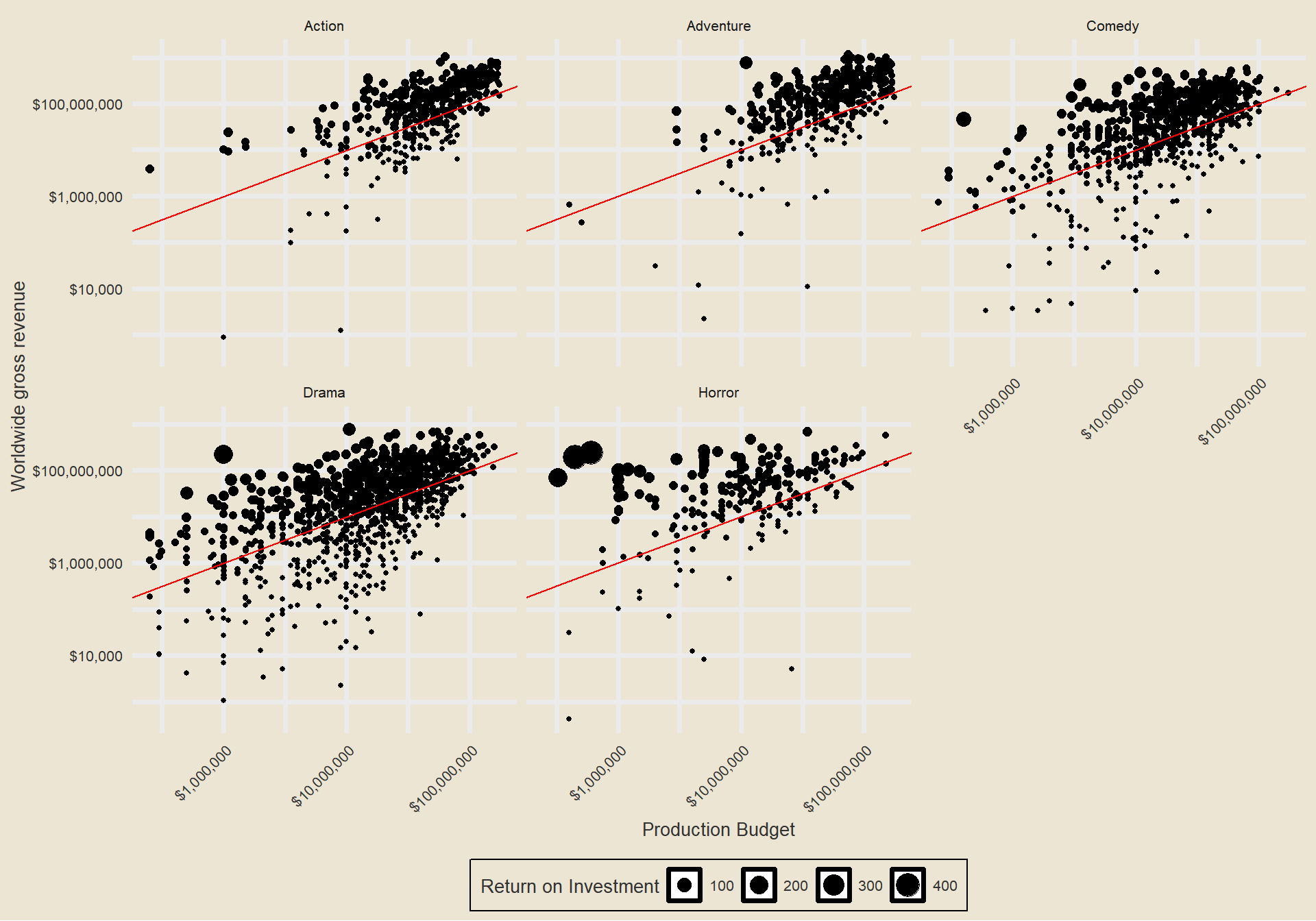
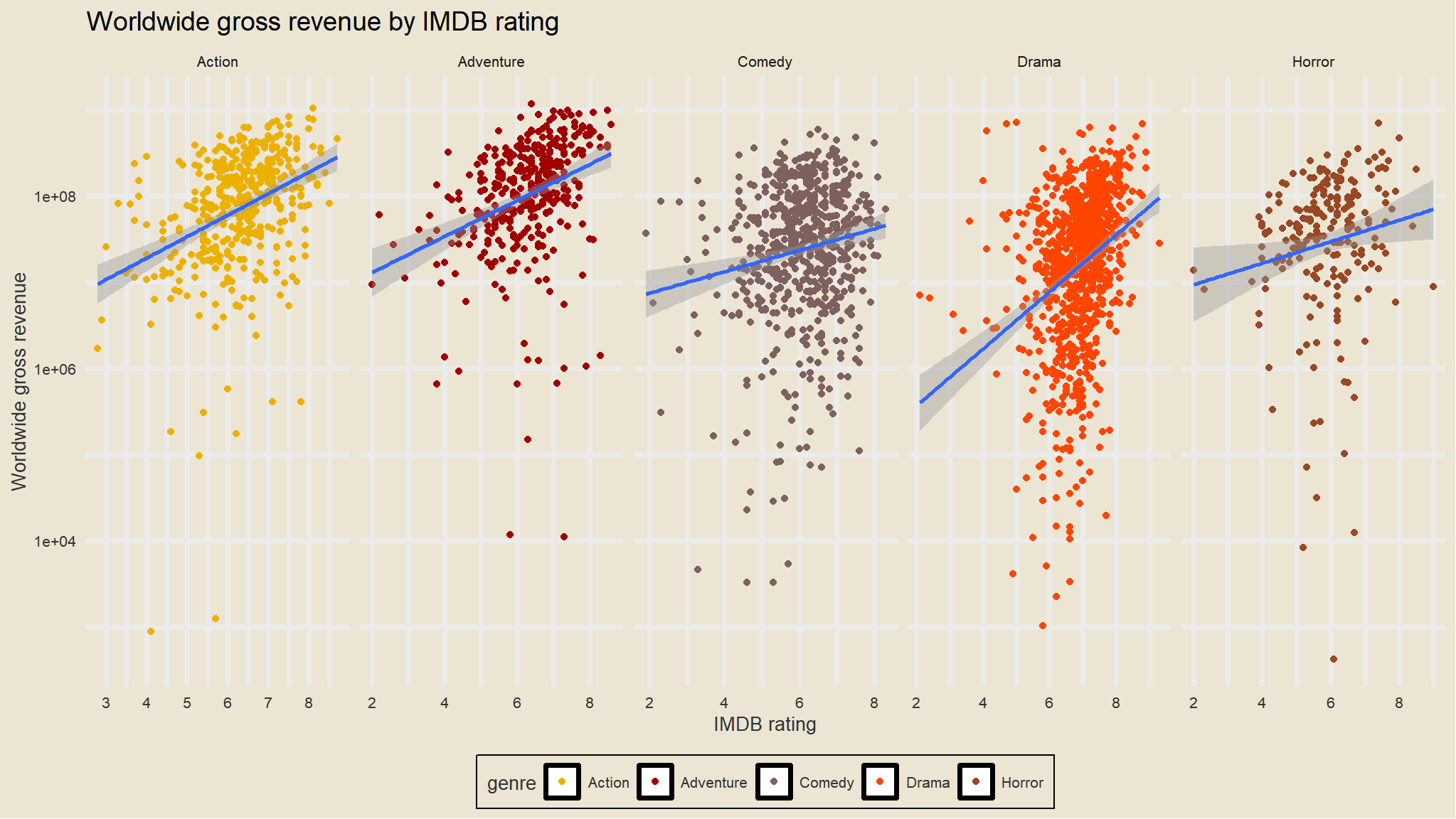
Let’s make a scatter plot showing the worldwide gross revenue over the production budget and let us facet by genre.
Generally most of the points lie above the “breakeven” line. This is good – if movies weren’t profitable they wouldn’t keep making them. Proportionally there seem to be many more larger points in the Horror genre, indicative of higher ROI.
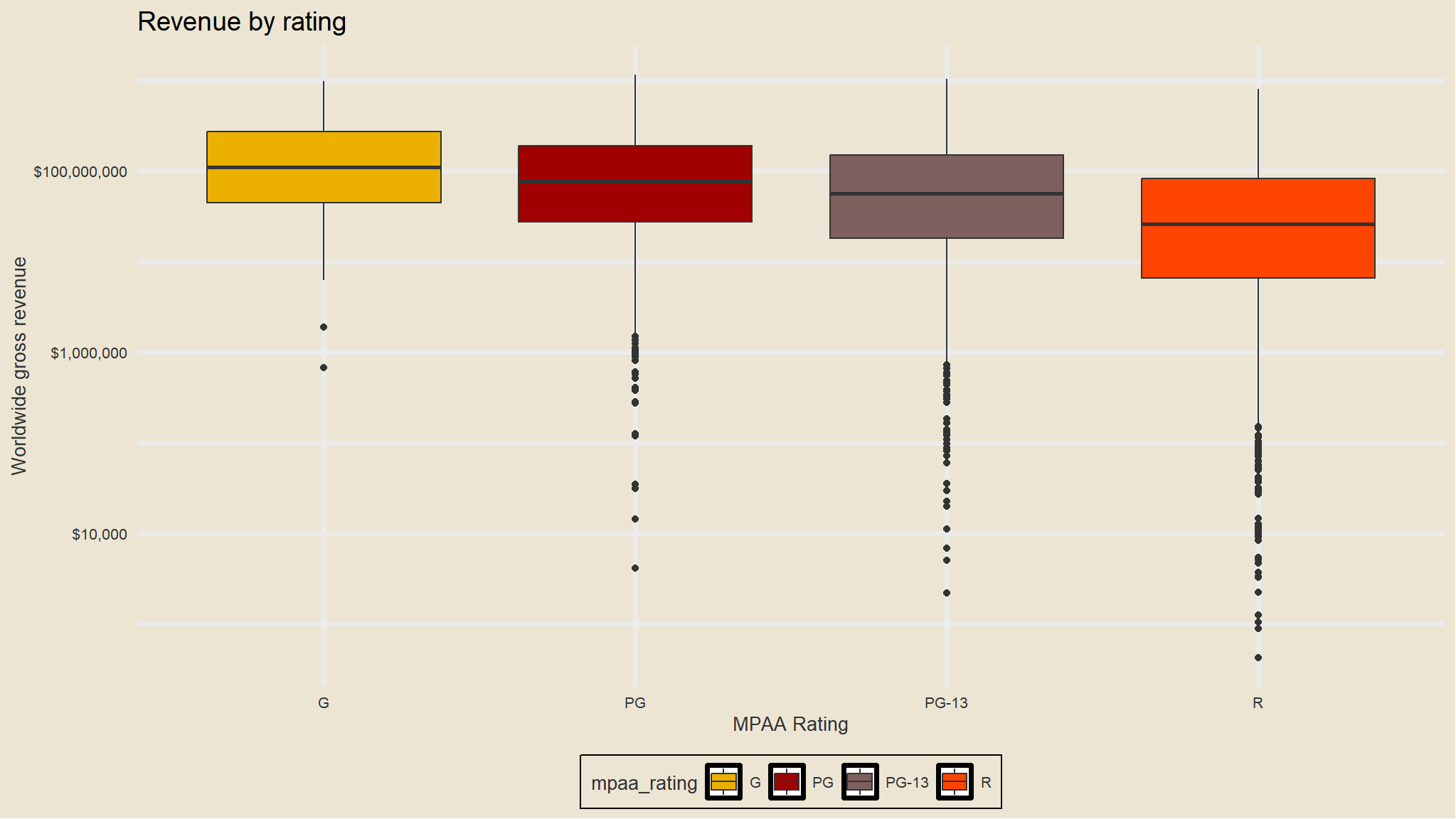
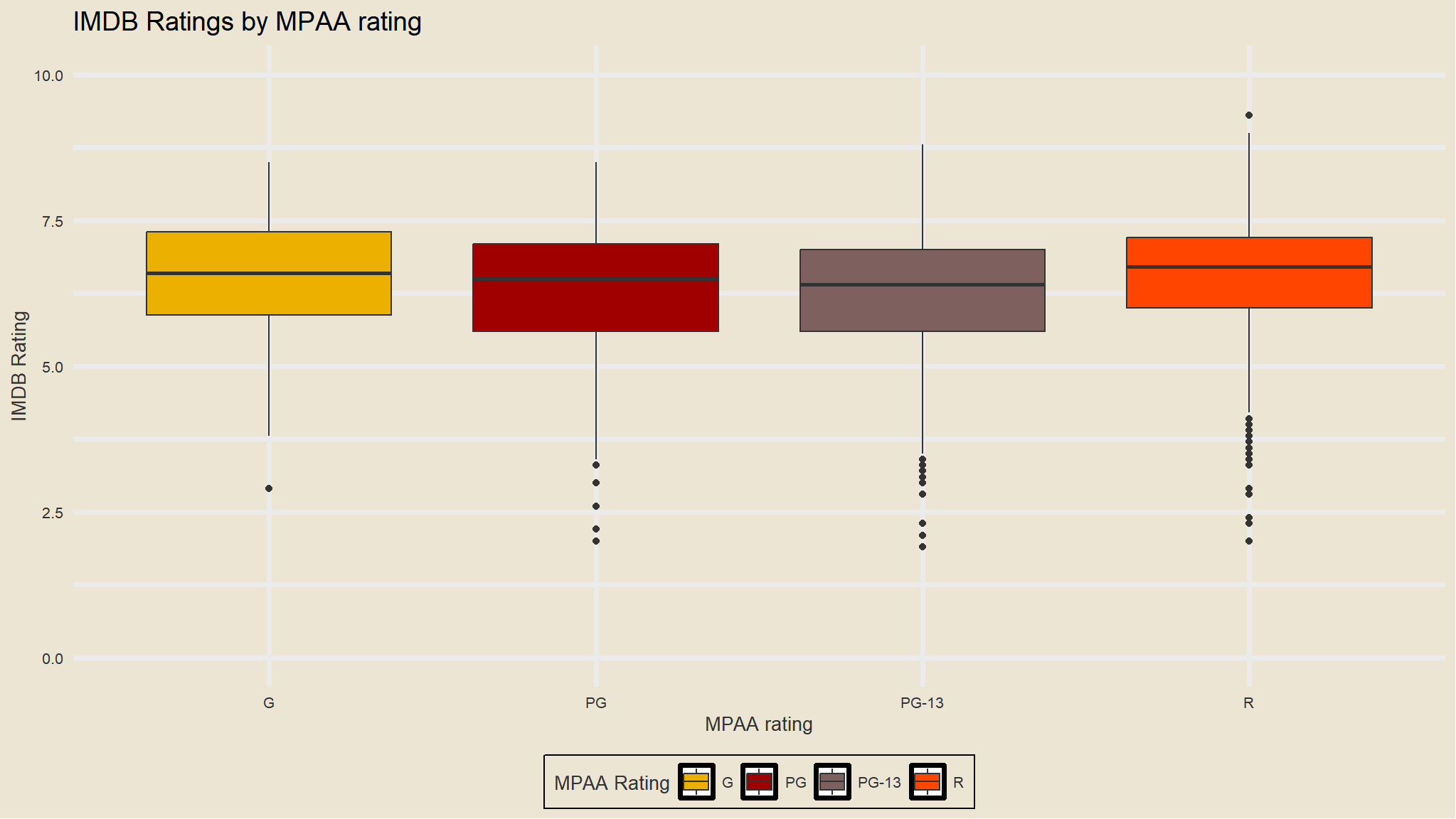
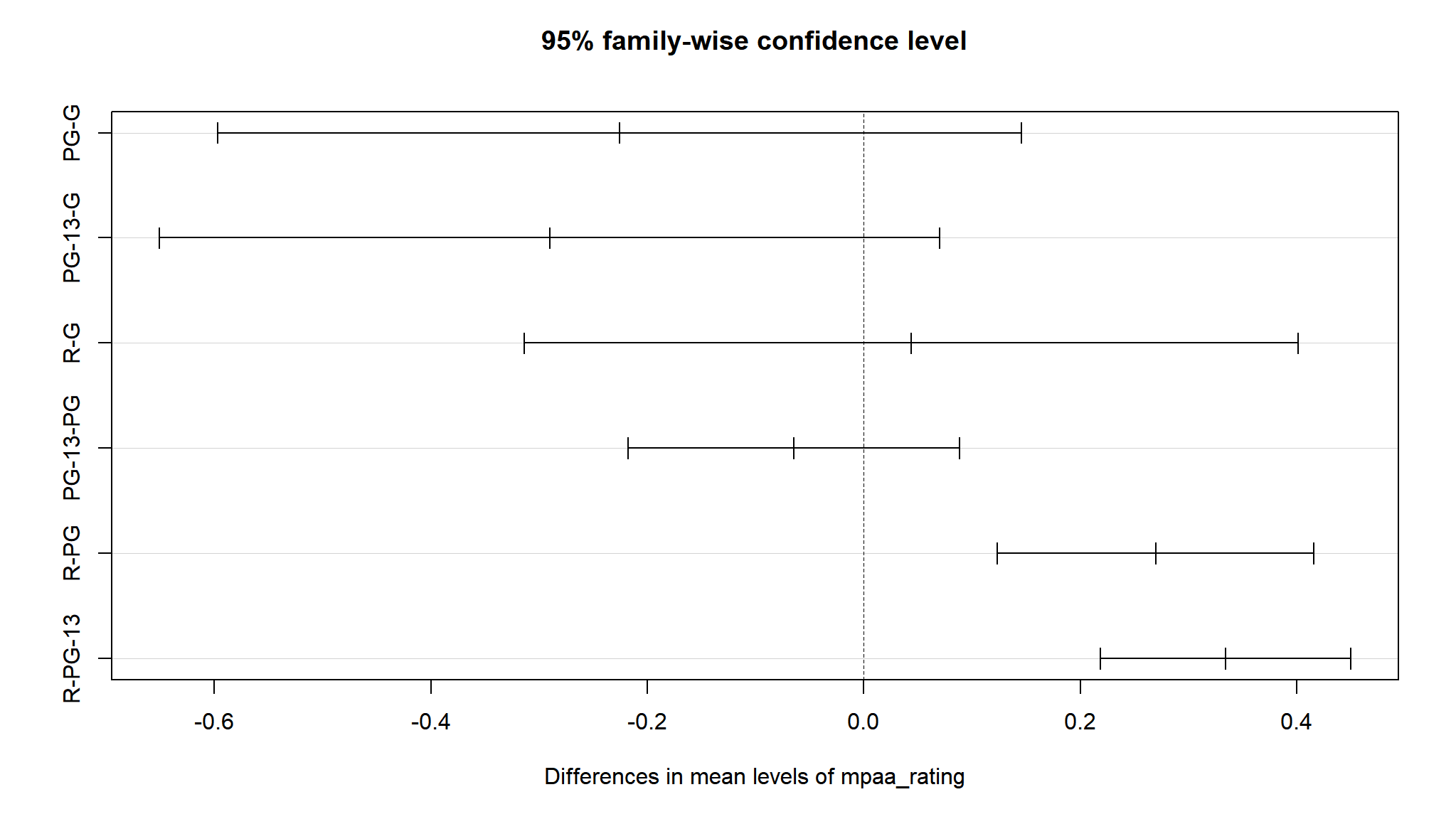
R-rated movies have a lower average revenue but ROI isn’t substantially less. We can see that while G-rated movies have the highest mean revenue, there were relatively few of them produced, and had a lower total revenue. There were more R-rated movies, but PG-13 movies really drove the total revenue worldwide.
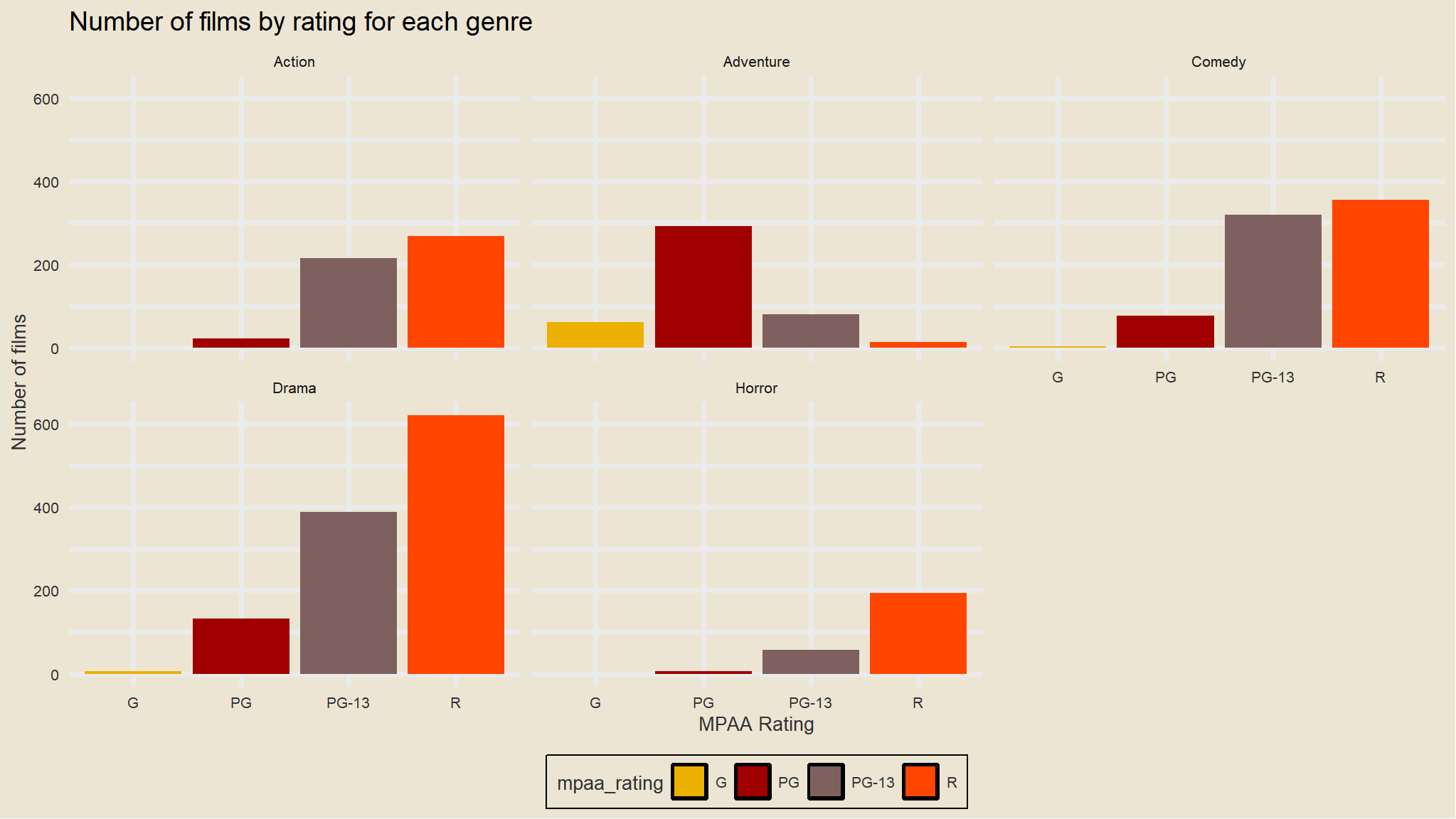
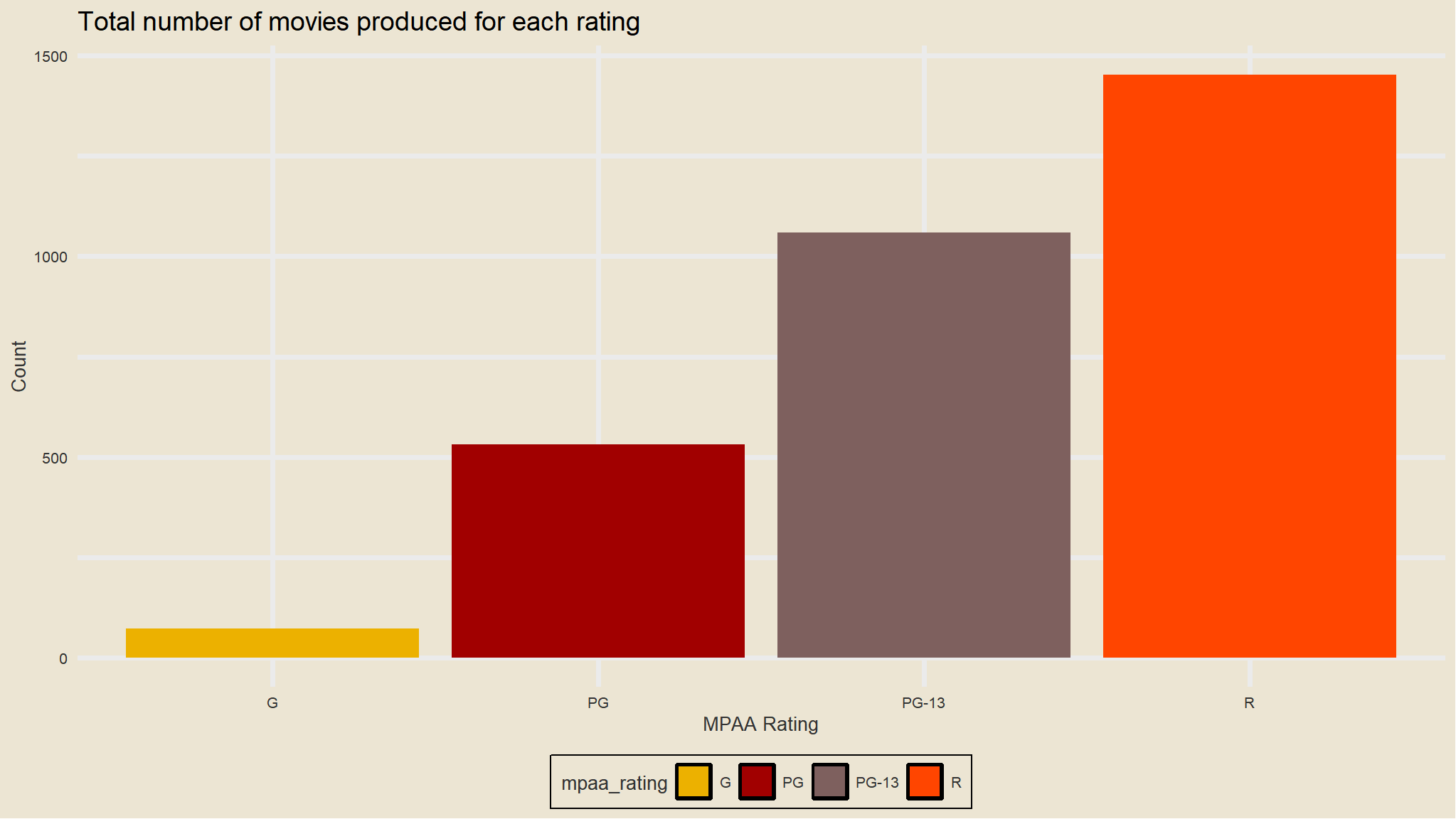
Are there fewer R-rated movies being produced? Not really. Let’s look at the overall number of movies with any particular rating faceted by genre.
mov |>count(mpaa_rating, genre) |>ggplot(aes(mpaa_rating, n,fill=mpaa_rating)) +geom_col() +theme_avatar()+scale_fill_avatar()+facet_wrap(~genre) +labs(x="MPAA Rating",y="Number of films", title="Number of films by rating for each genre")
What about the distributions of ratings?
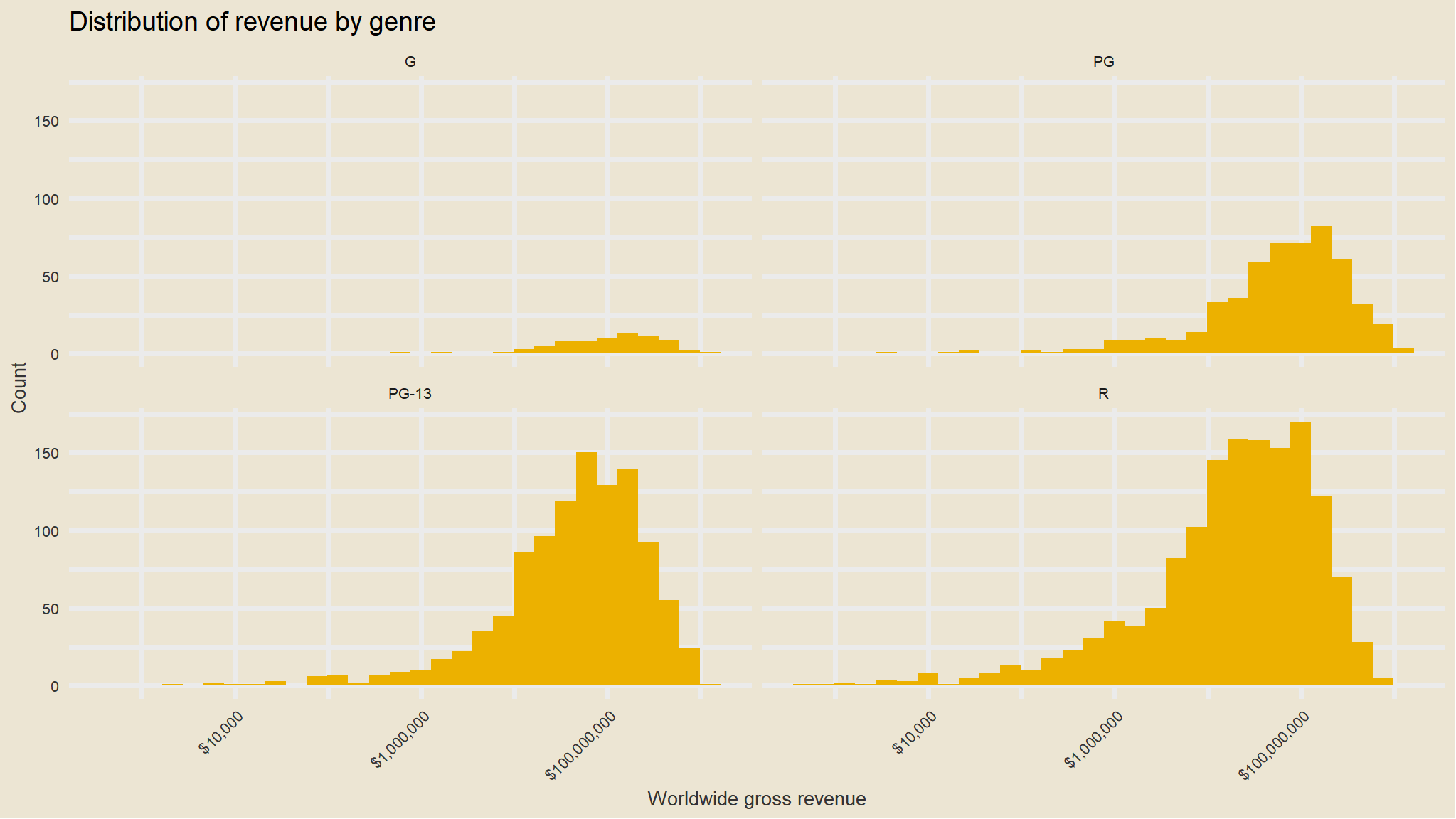
mov |>ggplot(aes(worldwide_gross)) +geom_histogram(fill=avatar_pal()(1)) +facet_wrap(~mpaa_rating) +theme_avatar()+scale_x_log10(labels=dollar_format()) +labs(x="Worldwide gross revenue", y="Count",title="Distribution of revenue by genre")+theme(axis.text.x =element_text(angle =45, hjust =1))
Yes, on average G-rated movies look to perform better. But there aren’t that many of them being produced, and they aren’t bringing in the lions share of revenue.
mov |>count(mpaa_rating) |>ggplot(aes(mpaa_rating, n,fill=mpaa_rating)) +theme_avatar()+scale_fill_avatar()+geom_col() +labs(x="MPAA Rating", y="Count",title="Total number of movies produced for each rating")
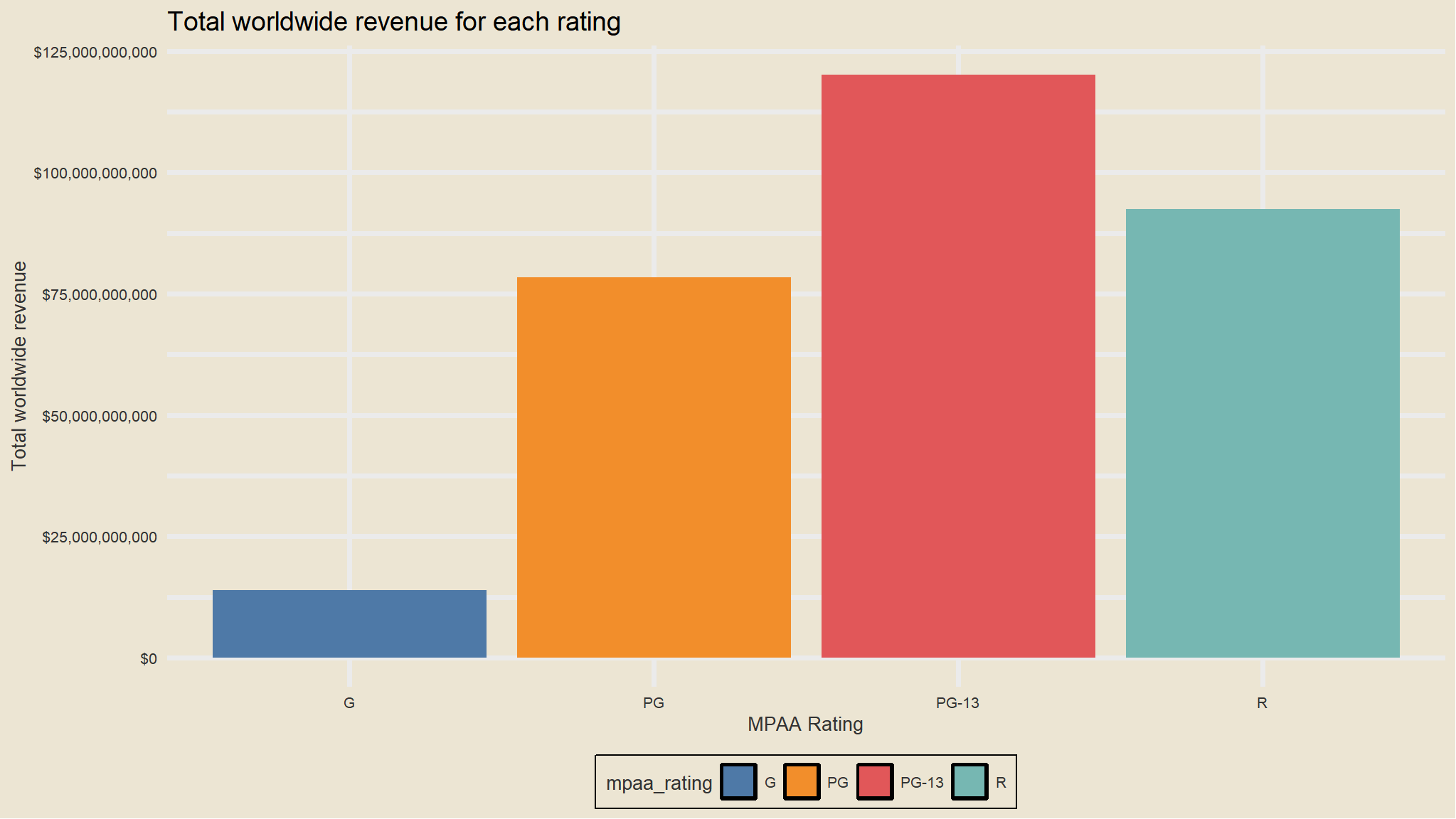
mov |>group_by(mpaa_rating) |>summarize(total_revenue=sum(worldwide_gross)) |>ggplot(aes(mpaa_rating, total_revenue ,fill=mpaa_rating)) +geom_col() +scale_fill_tableau()+theme_avatar()+scale_y_continuous(label=dollar_format()) +labs(x="MPAA Rating", y="Total worldwide revenue",title="Total worldwide revenue for each rating")
PG-13 Seems to bring in more revenue worldwide
but wait , is there any association between genre and mpaa_rating?
# Create frequency table, save for reuseptable <- mov %>%# Save table for reuseselect(mpaa_rating, genre) %>%# Variables for tabletable() %>%# Create 2 x 2 tableprint() # Show table#> genre#> mpaa_rating Action Adventure Comedy Drama Horror#> G 0 62 4 7 0#> PG 23 293 77 133 6#> PG-13 215 80 319 388 57#> R 268 14 356 621 194
CHI-SQUARED TEST
# Get chi-squared test for mpaa_rating and genreptable %>%chisq.test()#> #> Pearson's Chi-squared test#> #> data: .#> X-squared = 1343.7, df = 12, p-value < 2.2e-16
great ,p-value is less than 0.05 hence we can tell that genre and mpaa_rating are greatly associated .
let us Join to IMDB reviews dataset and get more insights
imdb <-read_csv("movies_imdb.csv")head(imdb)
let us inner join the two datasets together
do not worry , i will share another tutorial on performing joins exclusively ,otherwise you can check one of my tutorials that compares SQL and R
Correlation measures the strength and direction of association between two variables. There are three common correlation tests: the Pearson product moment (Pearson’s r), Spearman’s rank-order (Spearman’s rho), and Kendall’s tau (Kendall’s tau).
Use the Pearson’s r if both variables are quantitative (interval or ratio), normally distributed, and the relationship is linear with homoscedastic residuals.
The Spearman’s rho and Kendal’s tao correlations are non-parametric measures, so they are valid for both quantitative and ordinal variables and do not carry the normality and homoscedasticity conditions. However, non-parametric tests have less statistical power than parametric tests, so only use these correlations if Pearson does not apply.
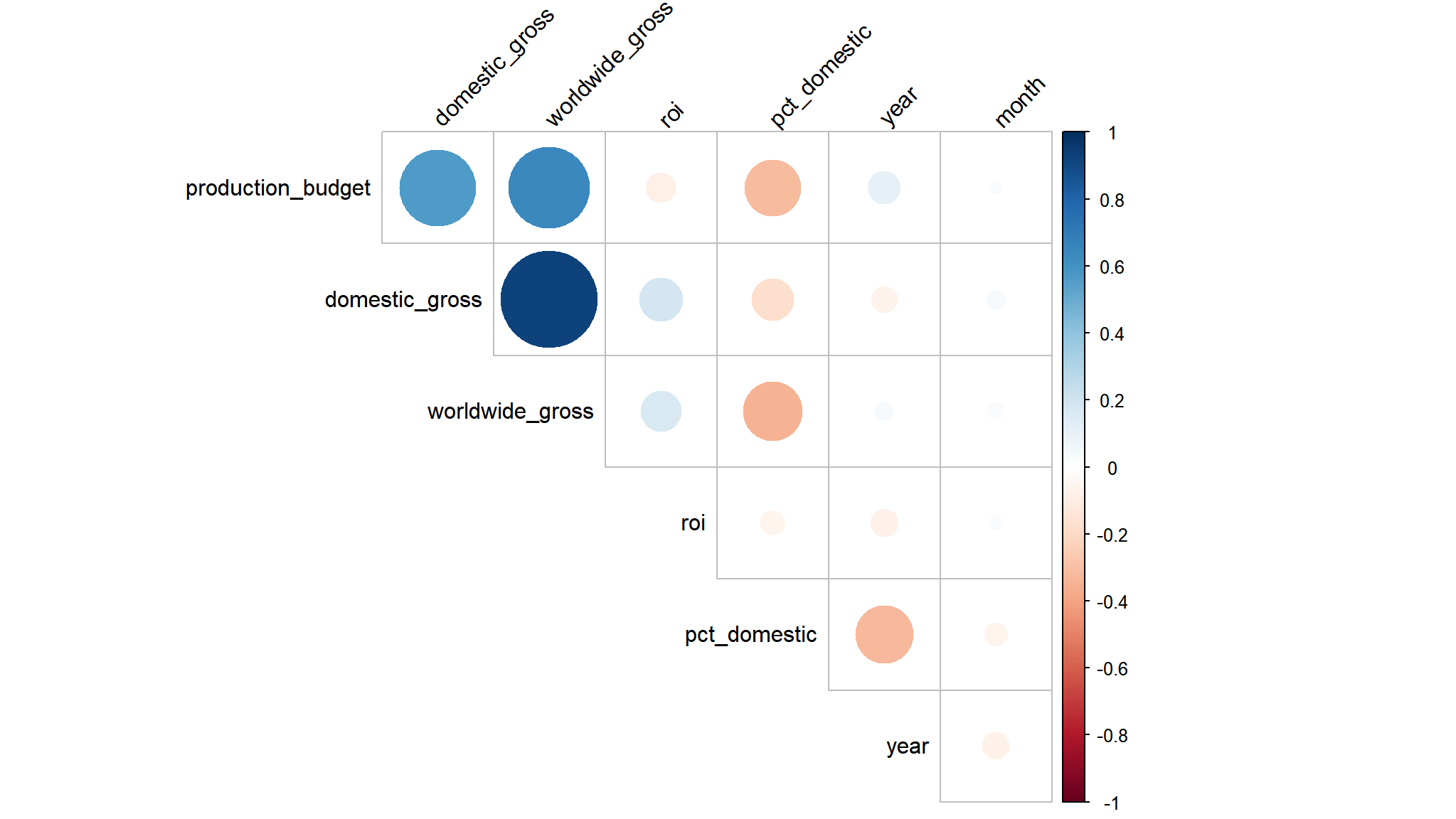
Visualize correlation matrix with corrplot() from corrplot package
library(corrplot)df %>%cor() %>%corrplot(type ="upper", # Matrix: full, upper, or lowerdiag = F, # Remove diagonalorder ="original", # Order for labelstl.col ="black", # Font colortl.srt =45# Label angle )
production cost ,world wide gross and domestic gross all seem to be inter-correlated
but is it significant?
# SINGLE CORRELATION ######################################## Use cor.test() to test one pair of variables at a time.# cor.test() gives r, the hypothesis test, and the# confidence interval. This command uses the "exposition# pipe," %$%, from magrittr, which passes the columns from# the data frame (and not the data frame itself)df %$%cor.test(production_budget,worldwide_gross)#> #> Pearson's product-moment correlation#> #> data: production_budget and worldwide_gross#> t = 47.722, df = 3115, p-value < 2.2e-16#> alternative hypothesis: true correlation is not equal to 0#> 95 percent confidence interval:#> 0.6291207 0.6697034#> sample estimates:#> cor #> 0.649875
off course yes ,the correlation is statistically significant
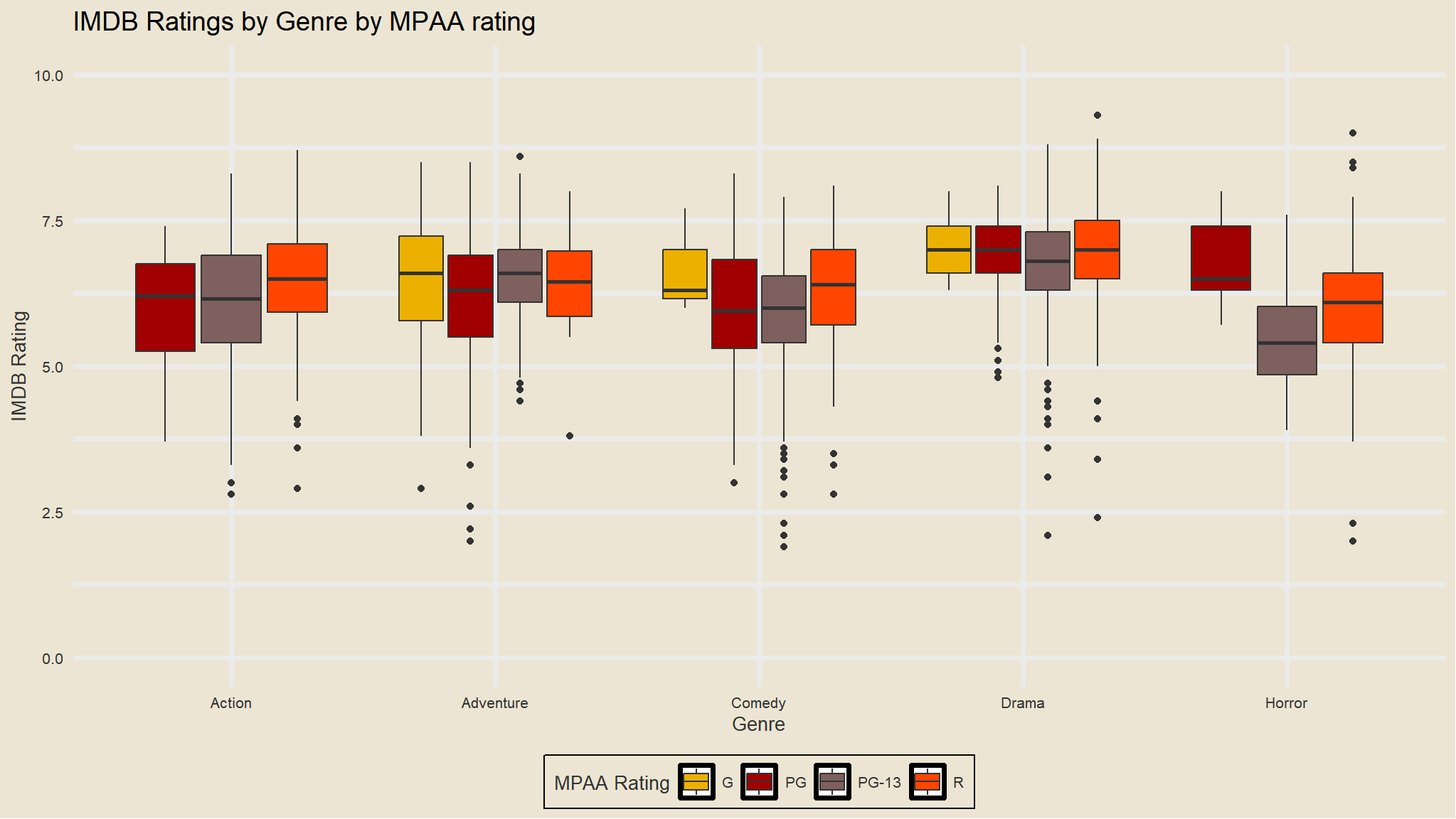
Separately for each MPAA rating, i will display the mean IMDB rating and mean number of votes cast.